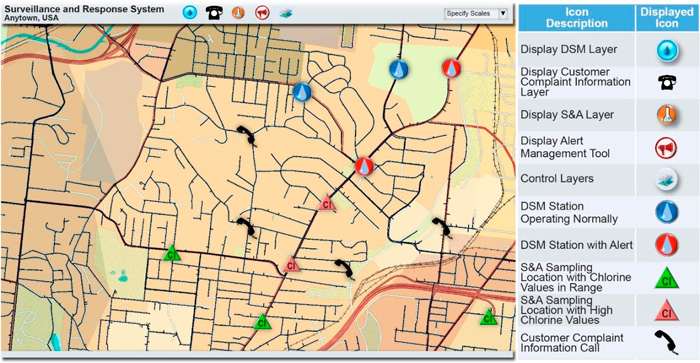
Los datos generados por las estaciones de medida del sistema de monitorización de calidad de agua deben ser convertidos en información que permita la toma de decisiones.
Esta conversión de los datos requiere el análisis de las cifras de las estaciones junto con la información complementaria disponible que permita la determinación de los comportamientos anómalos de parámetros que pueden ser identificados como eventos de contaminación. La presentación de los resultados de estos análisis debe hacerse de una forma fácilmente comprensible por el personal encargado de la toma de decisiones.
Es conveniente resaltar que la plataforma puede alimentarse de datos diferentes de los propios de los instrumentos que integran el sistema de calidad (p.e. estado de válvulas, presiones y caudales circulantes, estado de comunicaciones, etc.) que pueden proporcionar información relevante sobre la validez de los obtenidos por los mecanismos del sistema y ser incluidos en el método de análisis y visualización a desarrollar. En este sentido resulta relevante recordar que, por ejemplo, en los Estados Unidos, solamente el 10-15% de la información recogida por los gestores de agua es analizada de forma habitual, por lo que las herramientas de análisis y visualización representan también una gran oportunidad para mejorar este ratio de utilización de la información.
Un primer paso en el examen de la información es la validación de los datos obtenidos, puesto que la existencia de datos inválidos o poco fiables es inevitable en cualquier sistema ya sea debido al mal funcionamiento de un instrumento o línea de comunicación, a irregularidades en los caudales y presiones de operación o a tareas de mantenimiento.
La validación de los datos, necesaria para maximizar los beneficios y la sostenibilidad del sistema, así como para generar confianza en la operación del mismo, comprende la identificación de las cifras inexactas de forma que estas puedan ser tratadas de una forma que no interfiera con su uso y análisis posterior.
Los datos generados por las estaciones de medida del sistema de monitorización de calidad de agua deben ser convertidos en información que permita la toma de decisiones
Un primer nivel de validación se basa en el valor de los propios datos, como, por ejemplo, los valores de parámetros fuera del rango de medida del instrumento o aquellos nulos o no numéricos. Estos datos deben considerarse inválidos y ser gestionados adecuadamente.
Un segundo nivel de validación puede comprender el análisis de patrones en los valores de los datos de un instrumento, pudiendo considerarse inválidos o no utilizables los obtenidos durante periodos “planos” (valores constantes) o durante etapas de extremada variabilidad en frecuencia y magnitud que pueden indicar cambios físicamente imposibles.
Un nivel adicional de validación de los datos puede comprender el análisis conjunto de varios parámetros del sistema de calidad para los que se conoce que existe una correlación física, o incluso externos al mismo (p.e. programación de tareas de mantenimiento, estado de válvulas y flujos del sistema, etc.).
Estos procesos de gestión automática deben tener reglas claras para la sustitución de los datos considerados como inválidos por valores que se considere representan más adecuadamente el comportamiento de los instrumentos.
Además de estos procesos de identificación de datos inexactos, el sistema de gestión también debería permitir al usuario validar datos de forma manual, admitiendo que este marcara datos como inválidos sobre la base de información no existente en el sistema.
Con independencia del sistema de validación de datos que se implemente, es una buena práctica mantener siempre una copia completa de los originales, sin validar, para garantizar la integridad de las cifras y en caso necesario analizar la afección de distintos sistemas de comprobación y de sustitución de datos inválidos.
La validación de los datos puede constituir un proceso independiente dentro del sistema de información previa al mismo o estar incluida en el propio procedimiento. Asimismo, conviene considerar que algunos instrumentos avanzados ya realizan parte de la validación de los datos y proporcionan señales adicionales de detección de fallos a través de códigos específicos de error que deberán ser analizados por el sistema de información.
El resultado de la validación de datos es la creación de una reseña completa para el análisis de detección de anomalías. No conviene olvidar que debido al propio proceso de comprobación y sustitución de datos inválidos no puede tenerse una certeza absoluta de que este conjunto de datos sea completamente preciso.
La detección de anomalías o de eventos de contaminación es la identificación de cambios en la calidad de agua que requieren atención por parte del personal y que precisan de la toma de acciones de verificación o correctivas.
El resultado de la validación de datos es la creación de una reseña completa para el análisis de detección de anomalías
Si bien la detección de irregularidades podría ser realizada de forma visual por los operadores sobre las series disponibles, la cantidad de información y la complejidad de las variaciones en las mismas hacen que sea necesario el empleo de técnicas de análisis automatizadas que constituyen el centro de los sistemas de detección de eventos de contaminación.
Al hablar de sistemas automáticos de detección conviene resaltar la diferencia conceptual que existe entre una anomalía y un evento de contaminación. Las anomalías son valores puntuales en el tiempo en los que la calidad del agua no se corresponde con lo esperable, pero que no necesariamente son causa de alarma, mientras que un evento de contaminación es una anomalía continuada en el tiempo que sí debe de ser considerada una causa de alarma.
Las técnicas de detección de anomalías, de las que nos ocuparemos con más detalle en otro artículo posterior, presentan diferentes grados de complejidad y precisión y pueden considerarse englobadas en tres grandes grupos:
- Análisis de valores límites: se genera una alerta de anomalía en el momento en el que el valor de un parámetro supera, o es inferior, a un valor prefijado que representa los valores aceptables o habituales del parámetro (p.e. PH inferior a 6 o superior a 8). Se trata de un proceso de fácil implementación y que de forma general se encuentra implantado en todos los sistemas (incluso en el propio SCADA que gestiona los datos o en el propio instrumento).
- Análisis de conjunto: que analiza de forma agregada los valores de más de un parámetro, ya sea de dos relacionados en una misma localización o del mismo en dos localizaciones diferentes. Así, por ejemplo, en una estación una variación del oxígeno disuelto debería llevar asociado un cambio específico en, por ejemplo, la conductividad, que en caso de no darse generaría una alerta de anomalía. Como otro ejemplo, la medida de cloro residual en un dispositivo debería guardar una correlación, o bien estable o bien basada en el caudal, con la medida en otra estación ubicada aguas abajo en un instante posterior que depende del tiempo de tránsito hidráulico entre ambas estaciones, por lo que. si ambas medidas en dichas estaciones no se mantienen en unos rangos esperados, se generaría una alerta de anomalía.
- Análisis de series temporales: utilizan algoritmos complejos que permiten analizar la evolución de una o más series temporales o la progresión de las relaciones entre ellas (de un mismo parámetro en diversas localizaciones o de varios parámetros en una misma localización) para la generación de alertas de anomalías.
El resultado del análisis de anomalías suele complementarse con un estudio de la continuidad de las mismas como paso previo a la generación de una alarma o la identificación de un evento de contaminación, de forma que se limiten los casos aislados sin escasa relevancia disminuyendo el número de falsos negativos (alarmas indicadas cuando realmente no existe alarma) del sistema y la fiabilidad del mismo. Para la transformación de una anomalía en un evento de contaminación, en una alarma, suele utilizarse un proceso de identificación estadístico denominado Discriminador de Eventos Binomiales, que evalúa la probabilidad de que se produzcan un número determinado de anomalías en una cantidad concreta de medidas.
Además de la realización de los análisis requeridos, el sistema debe gestionar la presentación de los datos y los resultados. Idealmente la plataforma debería contener toda la información gestionada por él mismo de una forma intuitiva para el usuario, incluyendo distintas funcionalidades adicionales.
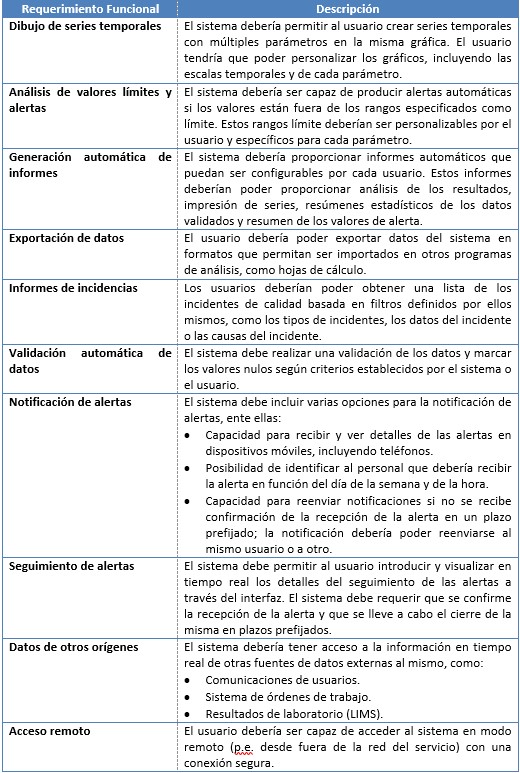
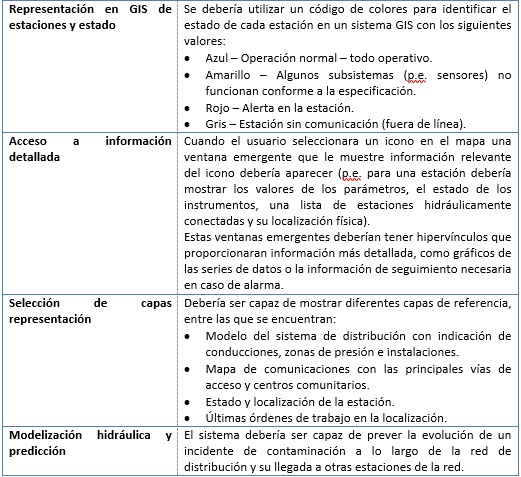
Entre los requerimientos funcionales de los sistemas de información pueden encontrarse los siguientes: