
Antes de comenzar a revisar los algoritmos más utilizados para la detección de eventos de contaminación resulta necesario matizar la diferencia conceptual entre una anomalía y un evento.
De forma general se considera como una anomalía en una serie de valores temporales a uno o más valores de la serie que se encuentran fuera del rango esperable para los mismos, pero cuya escasa continuidad en el tiempo puede ser atribuida a causas fortuitas (por ejemplo, un error en la medida o en la comunicación).
Por el contrario, se considera como un evento a un cambio continuado en los valores de una serie temporal cuya persistencia no puede ser atribuida a causas fortuitas, sino a una variación en los valores de este parámetro con un origen concreto que debe de ser investigado.
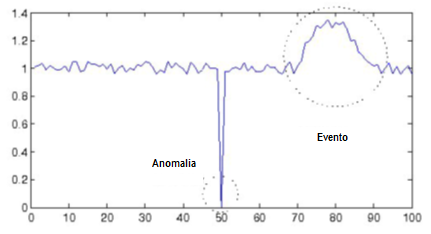
Esta diferenciación hace que los sistemas de detección de eventos de contaminación presenten dos fases básicas: la detección de anomalías y la identificación de las mismas como un evento.
La mayoría de los procedimientos de detección de contaminación tienen una fase posterior, mediante reconocimiento de patrones de comportamiento o de evolución, que permite identificar si un evento es normal en el funcionamiento de la red (por ejemplo, un cambio de calidad por la mezcla de agua de distintos orígenes) o si se trata de un suceso de contaminación, definido este como un imprevisto producido por una causa no habitual, desconocida.
Incluso algunos sistemas de detección de eventos pueden evaluar e identificar el origen probable de esta contaminación a través de la transformación conjunta de distintos parámetros y su comparación con evoluciones conocidas para distintos contaminantes.
Para la detección de anomalías pueden utilizarse desde el algoritmo más básico empleado para comparar el valor medido de un parámetro con unos valores límites de calidad a partir de los cuales se considera el valor medido como anómalo (por ejemplo, valores de pH fuera del rango habitual en la red), hasta modelos matemáticos (como EPANET) o sistemas basados en el conocimiento de la red con técnicas de inteligencia artificial (por ejemplo, redes neuronales).
Los algoritmos basados en límites, fijos o variables, si bien son muy útiles e incluso son implementados a nivel local por algunos sensores, presentan el problema de solo detectar cambios que alcancen dichos valores y no variaciones que puedan ser significativas pero que no alcanzan dicho valor límite.
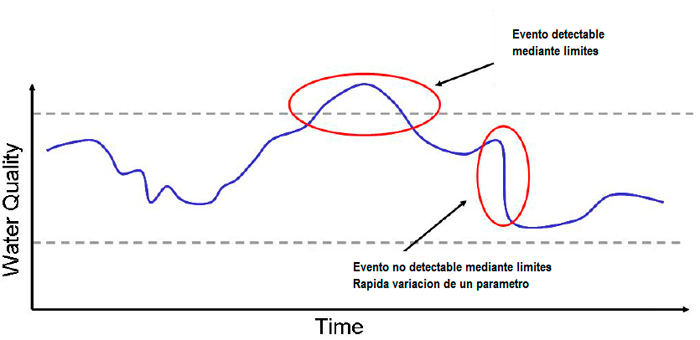
De cara a poder detectar este tipo de comportamiento se emplean algoritmos más completos basados en la predicción de valores: sobre la base de la serie temporal medida con anterioridad se predice el valor esperable del parámetro, el cual se compara con el valor realmente medido, evaluándose de esta forma el residuo entre ambos. Esto permite, en caso de ser mayor de un determinado valor, clasificar el valor medido como una anomalía (que posteriormente se evaluara si constituye o no un evento).
Para llevar a cabo la predicción debe de definirse la duración del histórico a considerar, ya que la bondad de la misma dependerá de la historia examinada. Normalmente se trabaja con la serie normalizada (con media de cero y desviación típica de uno) de forma que se pueda llevar a cabo una comparación homogénea con independencia de los valores concretos de la serie.
Para la predicción suelen utilizarse dos algoritmos básicos:
- El filtro de predicción de coeficientes lineales (LPCF): que procesa cada señal de forma independiente evaluando el valor previsto para cada serie mediante técnicas estadísticas autoregresivas de media móvil.
- El de proximidad multivariante (MVNN), en el que se evalúa el comportamiento conjunto de determinadas variables (n) consideradas como puntos en un espacio de n dimensiones, calculándose la distancia entre el punto medido y el procedente de la predicción. Este algoritmo realmente no proporciona los valores de los parámetros de calidad, sino que proporciona una valoración de la similitud (a través de la distancia en el espacio n dimensional) de la predicción con los valores medidos previos.
Sobre los distintos algoritmos a emplear, y puesto que cada uno tiene sus ventajas e inconvenientes, puede añadirse una capa adicional de evaluación, un algoritmo de consenso, que permite agrupar los resultados individuales de los distintos algoritmos, ya sea considerando el valor máximo de cada uno de ellos, la media o la necesidad de que la anomalía se vea reflejada en los distintos algoritmos.
Cualquiera de estos algoritmos, u otros, permiten clasificar cada valor temporal como un valor anómalo o normal, permitiendo de esta forma la evaluación o discriminación entre anomalías y eventos a través de un discriminador binomial de eventos (BED).
El discriminador binominal de eventos no es un algoritmo de detección propiamente dicho, siendo realmente un algoritmo diseñado para integrar los resultados obtenidos para distintos instantes de tiempo y calcular la probabilidad de que estos constituyan un evento.
Para esto utiliza otra ventana temporal, llevando la cuenta del número de anomalías que se han producido y comparando estas con la probabilidad de que se produzca un determinado número de irregularidades si estas fueran debidas a un evento binomial (con solo dos valores posibles: positivo y negativo). En el momento en el que el número de anomalías calculadas supera un determinado valor de probabilidad, clasifica el conjunto de irregularidades como un evento.
De cara a poder detectar este tipo de comportamiento se emplean algoritmos más completos basados en la predicción de valores
Este discriminador de eventos suele tener a su vez un valor límite que define la duración máxima que resulta asimilable a un evento, ya sea por la previsión del mismo o por los procedimientos de investigación de eventos, de forma que una vez trascurrido este tiempo de respuesta (Event Time Out) el sistema considerara las futuras anomalías como un evento separado del primero.
De esta forma suele considerarse que un evento acaba o bien cuando se mantiene durante un tiempo máximo, marcado por el periodo establecido para considerar el fin de un evento, o bien por una vuelta a la normalidad, retornando la serie a los valores que resultan ordinarios en la misma (si bien con un posible cambio de escala en los valores de algunos parámetros).
Uno de los principales problemas de los sistemas de detección de eventos es la presencia de falsos positivos, es decir, las irregularidades detectadas por el sistema que realmente no se corresponden con un evento real, entendido como un comportamiento anómalo, sino con una operación habitual del sistema de distribución o de la calidad del agua.
En este sentido los sistemas de detección de eventos incluyen tecnologías de reconocimiento de patrones para examinar los cambios en la calidad del agua debidos a operaciones o características inherentes al propio sistema.
El reconocimiento de patrones se basa, de forma general, en la idea de agrupar las variaciones de los parámetros y sus trayectorias, asociándolas a polinomios de bajo orden de forma que sean los coeficientes de regresión de la serie, no los valores concretos de la misma, los que indiquen una similitud entre comportamientos. De esta forma, utilizando los valores históricos de las series pueden establecerse categorías, patrones de variación, para los distintos parámetros.
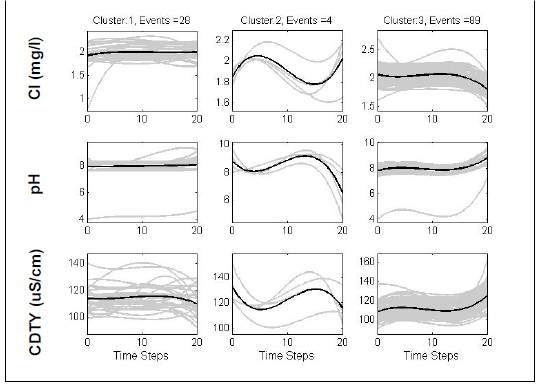
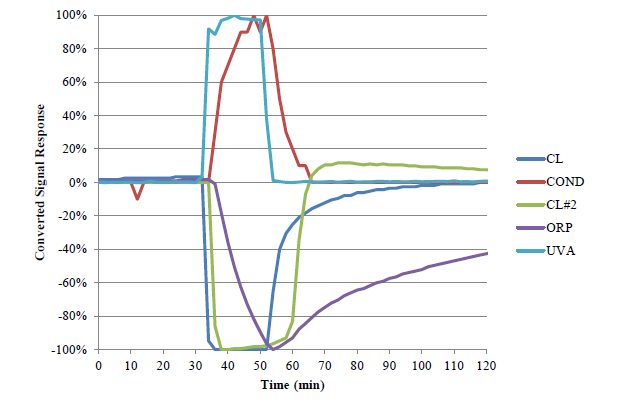
Por último, un sistema de detección de eventos de contaminación puede tener la capacidad de identificar de forma preliminar la presencia de un tipo de contaminante mediante el análisis conjunto de la evolución de cada uno de los parámetros de calidad, ya que el mismo provoca unas variaciones características en cada uno de los sensores instalados: